
Agentic AI vs. Autonomous Agents: The Essentials
-
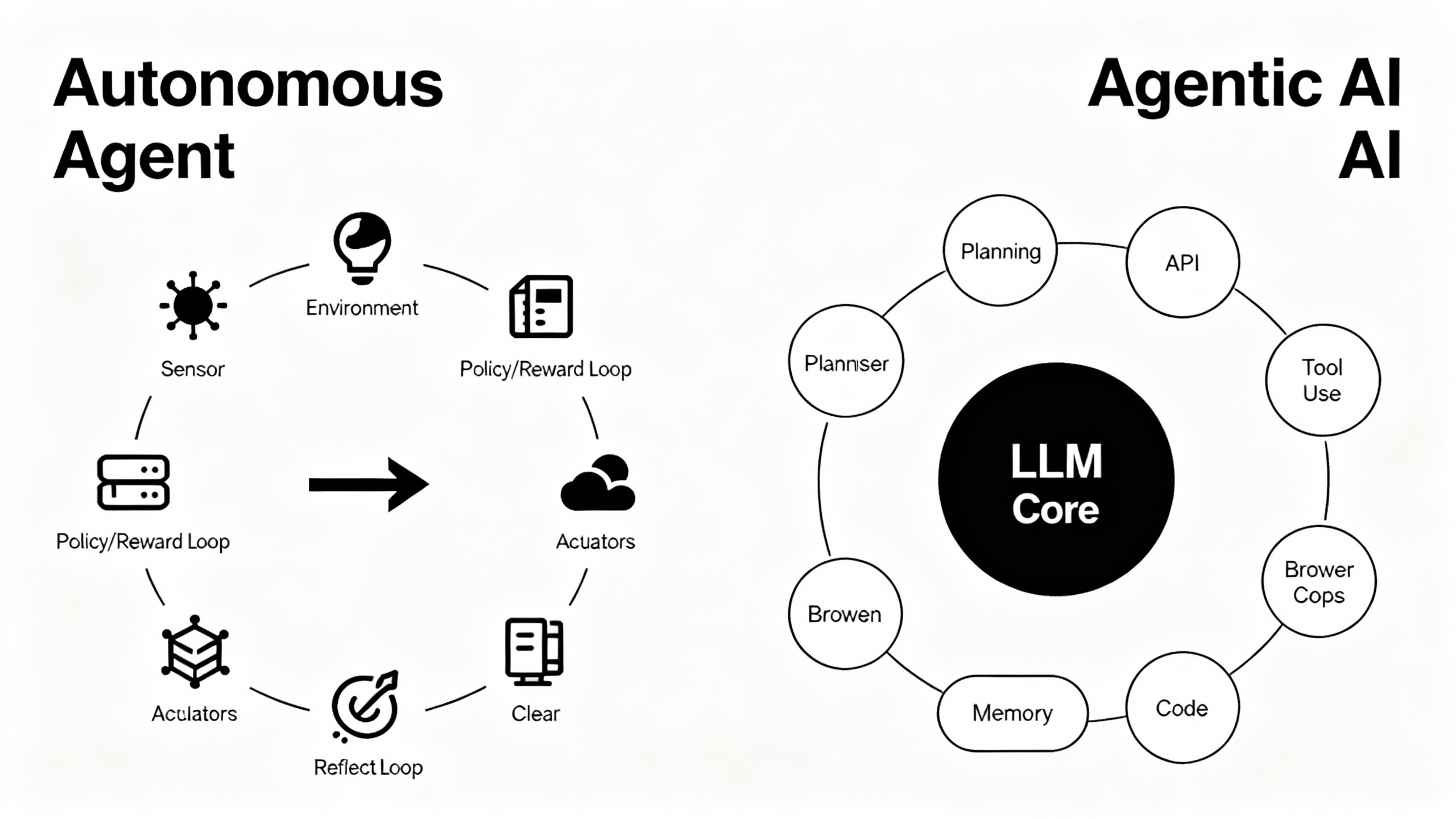
Definitions that stick Autonomous agents are software entities that perceive, decide, and act toward goals with minimal supervision—think the classical "agent" from AI textbooks like AIMA. Agentic AI describes a design pattern where large language models (LLMs) are given capabilities to plan, use tools, reflect, and iterate. A helpful primer is Microsoft Research’s overview, The Rise of Agentic AI.
-
Unit vs. behavior pattern "Autonomous agent" refers to a unit that operates within an environment (a trading bot, a warehouse robot, a simulation agent). "Agentic AI" is a behavior pattern you add to models—planning, tool-use, memory, feedback loops—often orchestrated by frameworks like LangGraph or LangChain Agents. You can build an autonomous agent that isn’t agentic, and you can add agentic behaviors to a non-autonomous workflow.
-
Autonomy dial vs. agency dial Autonomy measures how independently a system can act: from "suggest-only" to fully automated execution. Agency describes the system’s ability to set subgoals, plan steps, wield tools, and self-correct. You might keep autonomy low (human approval required) while dialing agency high (sophisticated planning), which is often safer for early deployments.
-
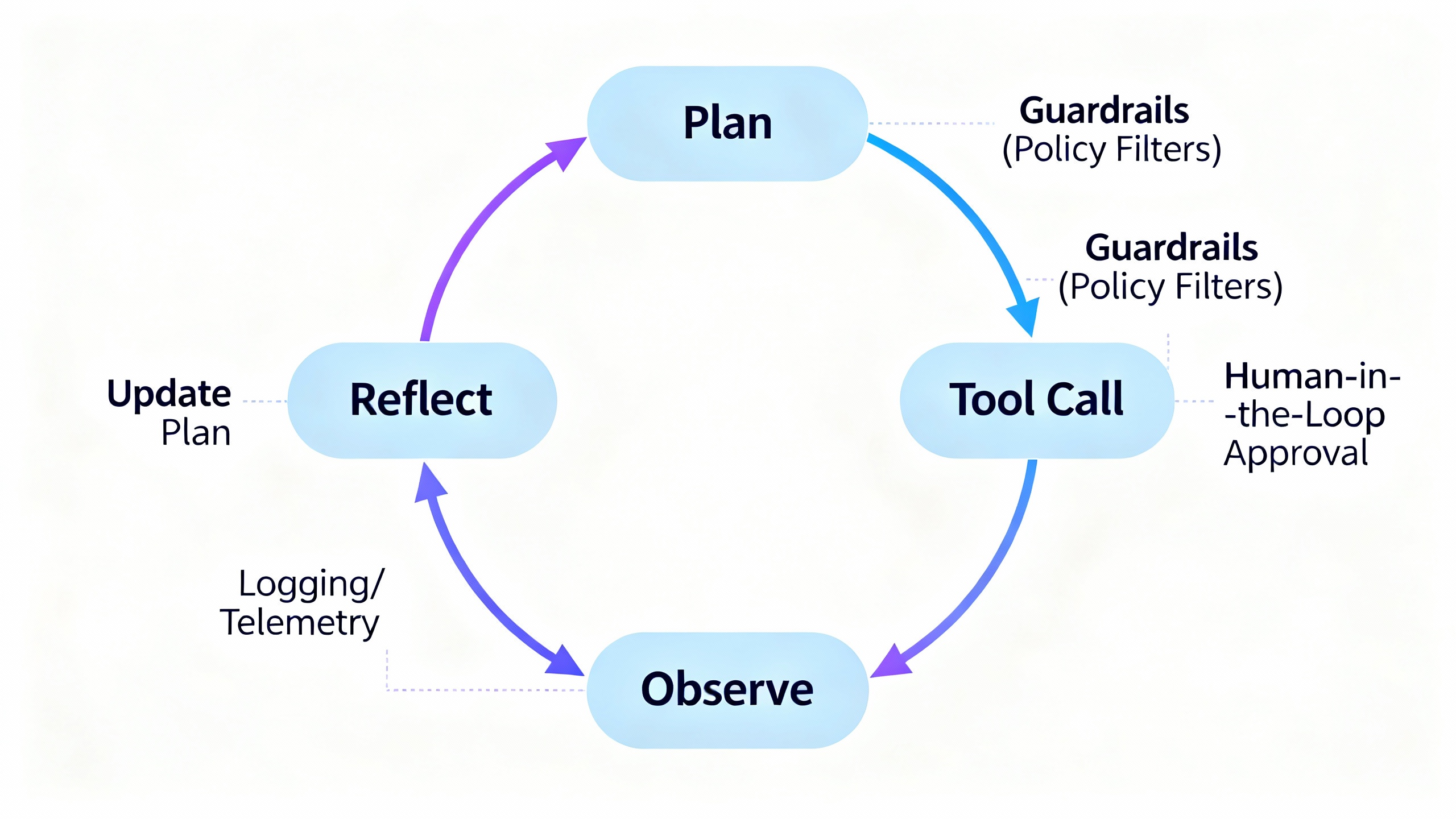
Under the hood: different cores Autonomous agents often use reinforcement learning, control theory, or rule-based policies—tuned via simulators and reward functions. Agentic AI relies on LLM-centric methods like ReAct (reasoning + acting), Reflexion (self-reflection loops), and multi-agent coordination frameworks such as AutoGen. These patterns let LLMs plan, call APIs, evaluate results, and iterate.
-
Decision signals: rewards vs. reasoning Classic autonomous agents optimize explicit reward signals and policies, often trained or evaluated in well-specified environments (OpenAI Spinning Up offers a good RL intro). Agentic AI leans on language priors, chain-of-thought reasoning, and tool feedback. It’s more heuristic and data-driven than reward-driven, which can be powerful in messy, open-ended tasks—but also less predictable.
-
Reliability and safety expectations Autonomous agents in physical or high-stakes domains emphasize formal verification, strict constraints, and rigorous testing. Agentic AI inherits LLM pitfalls: hallucinations, tool misuse, and prompt injection risks; counter with sandboxing, monitoring, and input/output filtering (see OWASP LLM Top 10 and Constitutional AI). A pragmatic approach is staged autonomy with strong observability and audit trails.
-
Where they shine Autonomous agents excel in stable, well-modeled environments—robotics, process control, and deterministic automations (e.g., RPA). Agentic AI thrives in knowledge work: research copilots, multi-step web tasks, data wrangling, and coding with tool calls (see Auto-GPT and OpenAI o1). If the task needs structured exploration and synthesis rather than precise control, agentic AI is often the faster win.
-
How they’re measured Autonomous agents are evaluated with task success, cumulative reward, sample efficiency, and safety metrics. Agentic AI is commonly benchmarked on multi-step task completion and tool-use effectiveness—examples include SWE-bench for code tasks and WebArena for web-based agency. In production, measure real business outcomes: time saved, error rates, cycle time, and operator handoff percentage.
-
Choosing (and combining) the two If your environment is well-specified and safety-critical, start with autonomous agents and clear constraints; if it’s fuzzy, text-heavy, and research-like, start agentic. Many teams combine them: agentic AI handles planning and knowledge work, then hands off to a bounded autonomous executor for reliable action.
TipA quick decision checklist
- Is the task open-ended and language-heavy? Favor agentic AI.
- Is the environment tightly modeled with clear rewards? Favor autonomous agents.
- Need both? Pair agentic planning with controlled executors, add human-in-the-loop gates, and log everything.



